Parallel Quicksort using OpenMP
Quicksort is one of the most commonly used sorting algorithms and it generally performs very well.
In this blog post we give a very brief overview of quicksort, show some of the most important pieces code and then discuss how to parallelise it using OpenMP in C++.
The structure of quicksort is the following:
You find a single element in the array (of length l), and reorder the array such that the following conditions hold:
a[j] ≤ a[p] ≤ a[k] for all 0≤ j < p, p ≤ k < l.
This means that you partition the array such that every element to the left of your pivot is smaller or equal to the pivot element and each element to the right is larger or equal. Now, if we could somehow magically sort each of these sections, then our array would be sorted right? So we just call quicksort on our two subarrays and off we go. The recursion stops when the size of the subarray is 1, as that is trivially sorted.
Now, why would you want to parallelise this? Even though the normal algorithm is quite fast already (if you choose a decent pivot element), most modern machines have multiple cores, so if there’s an easy way to speed up common tasks (and sorting is very common), then it’s definitely useful.
Here is the implementation of the serial quicksort algorithm. Assume the partition function does what is described above. It can be found in the github repo. This resource goes into great depth about choosing a pivot and performing the partitioning.
How do we parallelise it? OpenMP is a shared memory programming model that provides useful features for all manner of parallelisation across different processors in the same machine.
The component we will use today is the task construct. The process consists of a single thread (the master one) creating multiple tasks for each level of recursion and then all threads can perform tasks from that generated task queue. One notable factor is that we only generate tasks if the size of the array is larger than some threshold. This is done, because for too small workloads, the extra overhead of creating a task and assigning a thread to it becomes a significant part of the total time.
Here is the code for that, we simply add a few lines of pragmas and we’re done! OpenMP does all of the heavy lifting. We also need to defer to the serial version when the array size becomes small as described above.
This does require a way to create the parallel region, which basically tells OpenMP that the following needs to be executed in parallel. We use
#pragma omp singleto only generate the tasks only once, but execute them across threads.
To compile OpenMP code, you can simply use the command:
g++ file.cpp -fopenmp -o file.outAnd you need to include the <omp.h>header file.
Results
The code here was ran on my 4 core, 8 thread laptop running WSL.
Adding in those few lines of code definitely helps improve the runtime performance of quicksort. A few things: we could have used the sections construct with similar code. This was generally the way to do things long ago, and the more modern and preferred alternative is to use tasks. In my experience, tasks also perform better, because with sections, each thread only does the work for one section (which is equivalent to the tasks above), whereas each thread can perform the work of many tasks.
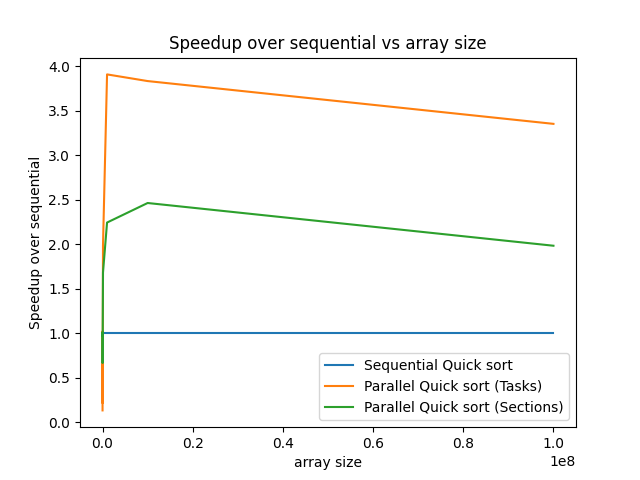
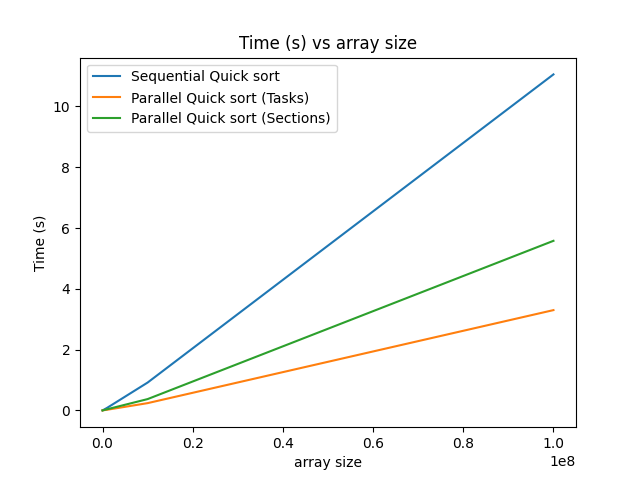
Conclusion
As we saw in this post, using OpenMP can drastically improve the performance of quick sort (and other sorting algorithms as well) with minimal code change. The github repository for this blog post can be found here.
References / Resources
A lot of this was based on labs and assignments we had for our parallel computing course.
You can find other useful resources here: